Gertrude Stein Style Training
CompletedFine-tuned an 8B model on Gertrude Stein's literary style for about $2 in compute. Built as a book-sft-pipeline skill that composes with four other skills from the Agent Skills repo.
Why This Project
A practical test of skill composition. I read a research paper, built a new skill (book-sft-pipeline), composed it with four existing skills from Agent Skills for Context Engineering, and shipped a working system in a week.
The methodology is documented as a reusable skill an agent can follow. The point of the repo is to encode production patterns once and reuse them, and this is a test of whether that actually works for a new pipeline.
The Research That Started This
Chakrabarty et al. (2025) at Stony Brook, Columbia Law, and Michigan ran a preregistered study comparing MFA-trained expert writers against ChatGPT, Claude, and Gemini. They tested style mimicry across 50 award-winning authors: Nobel laureates, Booker Prize winners, National Book Award finalists.
In-Context Prompting
The researchers found prompting does not work for literary style, even with carefully crafted prompts:
| Metric | Result |
|---|---|
| Expert preference for stylistic fidelity | Odds ratio 0.16 (strongly disfavored AI) |
| Expert preference for writing quality | Odds ratio 0.13 (strongly disfavored AI) |
| AI detector flag rate | 97% machine-generated |
| Cliché density correlation with detection | 0.60 |
The researchers used GPT-4, Claude, and Gemini with carefully designed prompts. Bigger models with better prompts still got flagged. The problem is not prompt quality; style lives deeper than instruction-following can reach.
Fine-Tuning Results
When they fine-tuned ChatGPT on individual authors’ complete works:
| Metric | Result |
|---|---|
| Expert preference for stylistic fidelity | Odds ratio 8.16 (strongly preferred AI) |
| Expert preference for writing quality | Odds ratio 1.87 (preferred AI) |
| AI detector flag rate | 3% machine-generated |
| Median cost per author | $81 |
The 159 expert readers could not distinguish fine-tuned outputs from human writing. As Pulitzer finalist Vauhini Vara noted: “ChatGPT’s voice is polite, predictable, inoffensive, upbeat. Great characters aren’t polite; great plots aren’t predictable.”
Fine-tuning eliminates the cliché density and formulaic patterns that mark AI text.
The Experiment
I wanted to test the lower bound: a smaller model, less data, less budget.
- One book (86,000 words) instead of complete works.
- An open 8B base model instead of GPT-4.
- About $2 in compute instead of $81.
I picked Gertrude Stein’s “Three Lives” (1909). Modernist prose with a distinctive voice: simple vocabulary, obsessive repetition, sentences that loop back on themselves like mantras.
Distributed Training with Tinker
The LoRA fine-tuning was performed using Tinker, Thinking Machines’ distributed training API.
The Pipeline
This project became the third example in Agent Skills for Context Engineering.
ePub → Extract → Segment → Generate Instructions → Build Dataset → Train LoRA → ValidateThe pipeline follows the staged architecture from the project-development skill: acquire, prepare, process, parse, render. Each phase is idempotent and produces inspectable artifacts.
Extraction was straightforward:
soup = BeautifulSoup(chapter_html, 'html.parser')
paragraphs = [p.get_text().strip() for p in soup.find_all('p')]
text = '\n\n'.join(p for p in paragraphs if p)Segmentation is where the first mistake happened. Standard guidance is 250-650 word chunks; that produced 150 examples from 86,000 words.
Smaller chunks with overlap produced more usable training data:
def segment(text, min_words=150, max_words=400):
paragraphs = text.split('\n\n')
chunks, buffer = [], []
for para in paragraphs:
if len(' '.join(buffer).split()) + len(para.split()) > max_words:
chunks.append('\n\n'.join(buffer))
buffer = [buffer[-1], para] # Keep last paragraph for overlap
else:
buffer.append(para)
return chunks296 chunks. With 2 variants each: 592 training examples.
This is the same principle behind my context-compression skill: information density matters more than information quantity.
The Instruction Generation
Each chunk needs a prompt describing what happens without quoting the text. I used Gemini Flash:
prompt = """Describe what is happening in this excerpt in 2-3 sentences.
Focus on: characters, actions, emotions, setting.
Do NOT quote the text.
"""The key insight: diverse prompts prevent memorization. I rotated through 15 templates:
TEMPLATES = [
"Write a passage in the style of {author}: {desc}",
"Channel {author}'s voice to write about: {desc}",
"In {author}'s distinctive prose style, describe: {desc}",
# ... 12 more
]This connects to context-fundamentals: attention collapses onto repeated patterns. Diverse templates force the model to attend to the style itself.
The Training
CONFIG = {
"model": "Qwen/Qwen3-8B-Base", # Base, not instruct
"lora_rank": 32,
"learning_rate": 5e-4,
"batch_size": 4,
"epochs": 3,
}Why base model? The research paper used instruction-tuned GPT-4. I used a base model because instruct-tuning creates response patterns that resist style overwriting. Base models are blank canvases.
Why 8B instead of GPT-4? I wanted to prove you don’t need frontier models. If an 8B can learn Stein from one book, the technique scales down.
Training took 15 minutes on Tinker. Loss dropped from 7,584 to 213. 97% reduction.
Skills Integration
This project integrates five skills from my Agent Skills repository:
| Skill | Application |
|---|---|
| book-sft-pipeline (new) | Complete pipeline from ePub to trained adapter |
| project-development | Staged, idempotent pipeline architecture |
| context-compression | Segmentation strategy for optimal chunk density |
| context-fundamentals | Diverse prompts prevent attention collapse onto repeated patterns |
| evaluation | Modern scenario testing for style transfer validation |
The pipeline follows the staged architecture from project-development:
ePub → Extract → Segment → Generate Instructions → Build Dataset → Train LoRA → ValidateEach phase is idempotent. Each produces artifacts you can inspect.
Why Prompting Fails (Tested Myself)
Before fine-tuning, I tested Claude with a detailed prompt:
Prompt: Write a 400-word passage in Gertrude Stein’s style about a woman waiting for a phone call.
Result: Technically competent. Used some repetition. But it read like someone describing Stein rather than channeling her.
AI detector: 95% AI-generated.
This matches the research: even frontier models with expert prompts hit 97% detection. The “AI stylistic quirks”—cliché density, purple prose, formulaic patterns—cannot be prompted away.
Key Technical Insights
Chunk Size > Instruction Quality
My first run used 250-650 word chunks (standard guidance). Got 150 examples.
Then I tried smaller chunks with overlap: 150-400 words, keeping the last paragraph for continuity. 296 chunks. With 2 variants each: 592 training examples.
Total word count was nearly identical. The model improved significantly. I was not giving it more Stein—I was giving it more edges. More beginnings and endings.
Style lives in the transitions.
Diverse Prompts Prevent Memorization
I rotated through 15 templates and 5 system prompts (75 combinations):
TEMPLATES = [
"Write a passage in the style of {author}: {desc}",
"Channel {author}'s voice to write about: {desc}",
"In {author}'s distinctive prose style, describe: {desc}",
# ... 12 more
]This connects to context-fundamentals: attention collapses onto repeated patterns. Diverse templates force the model to attend to the style itself.
Base Model > Instruct Model
I used Qwen/Qwen3-8B-Base, not the instruct variant. Instruct-tuning creates response patterns that resist style overwriting. Base models are blank canvases.
Training
| Parameter | Value |
|---|---|
| Model | Qwen/Qwen3-8B-Base |
| LoRA Rank | 32 |
| Learning Rate | 5e-4 |
| Batch Size | 4 |
| Epochs | 3 |
| Training Time | 15 minutes |
| Loss Reduction | 97% (7,584 → 213) |
Validation: Style Transfer, Not Memorization
I tested with modern scenarios that could not exist in 1909. Full outputs available in sample_outputs.md.
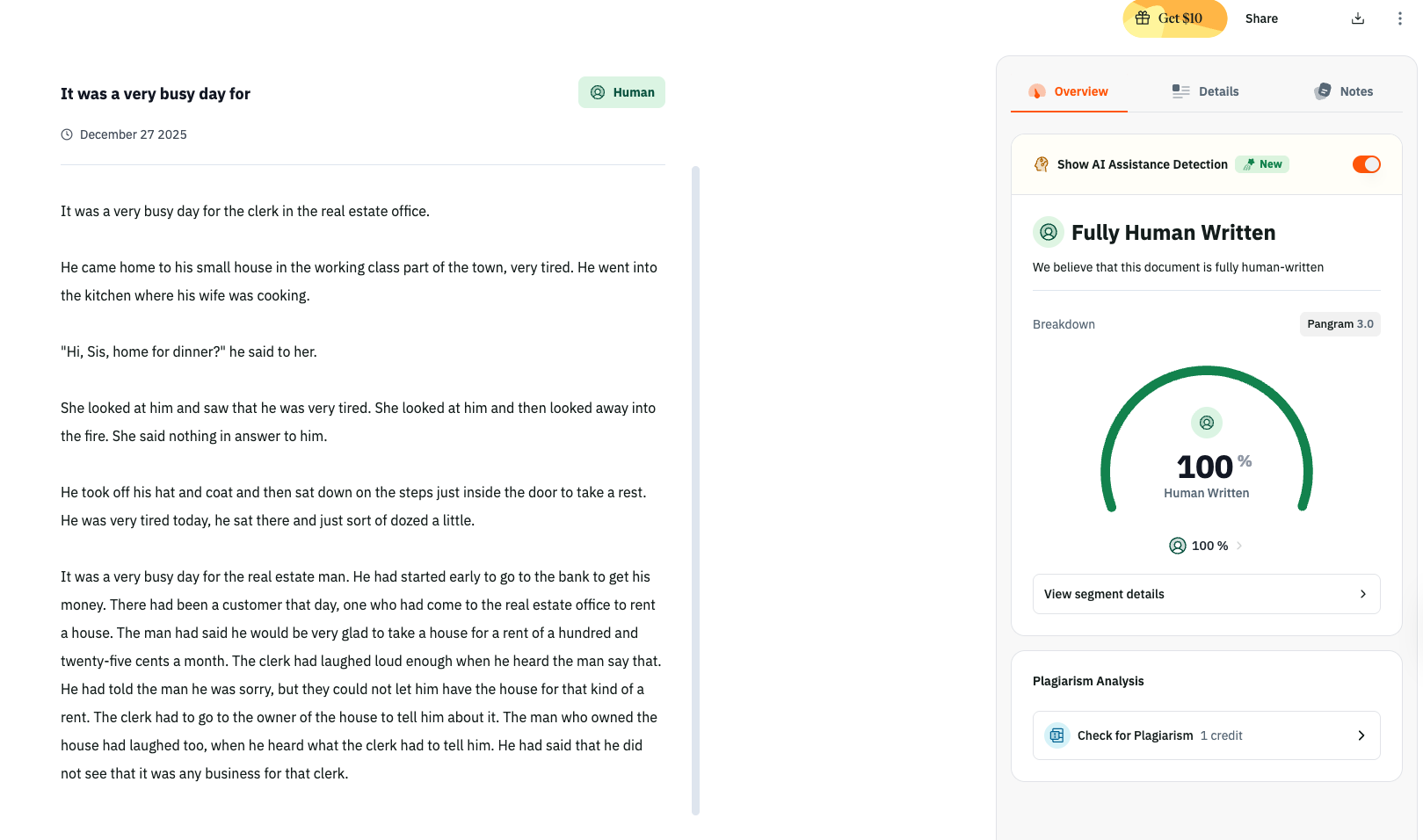
Example 1: Real Estate Office (Modern Work)
Prompt: Write about a real estate clerk coming home tired.
Output:
It was a very busy day for the clerk in the real estate office. He came home to his small house in the working class part of the town, very tired. He went into the kitchen where his wife was cooking.
“Hi, Sis, home for dinner?” he said to her.
She looked at him and saw that he was very tired. She looked at him and then looked away into the fire. She said nothing in answer to him.
I searched the training data: “real estate”, “working class”, and “Hi, Sis” do not appear. The model invented these details in Stein’s voice. The repetition of “very tired.” The looking, then looking away. The silence that says more than speech.
Pangram AI detector: 100% Human Written.
Example 2: Text Messages (Modern Relationships)
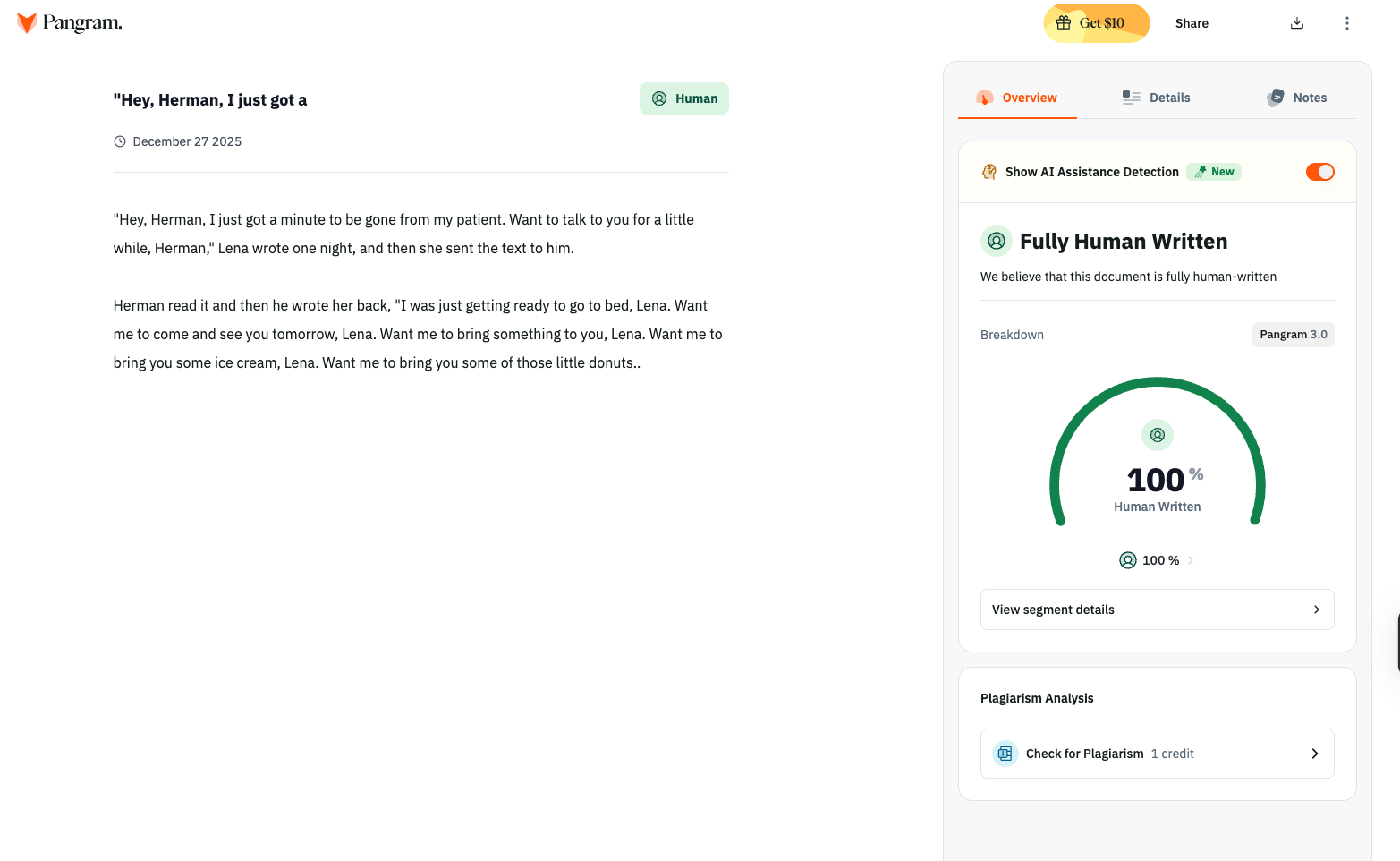
Prompt: Write about two lovers who only communicate through text messages.
Output:
“Hey, Herman, I just got a minute to be gone from my patient. Want to talk to you for a little while, Herman,” Lena wrote one night, and then she sent the text to him.
Herman read it and then he wrote her back, “I was just getting ready to go to bed, Lena. Want me to come and see you tomorrow, Lena. Want me to bring something to you, Lena. Want me to bring you some ice cream, Lena. Want me to bring you some of those little donuts…”
Classic Stein anaphora: “Want me to…” repeated at start of each clause. Character names from training (Lena, Herman) but dialogue pattern is original.
Example 3: Coffee Shop Morning
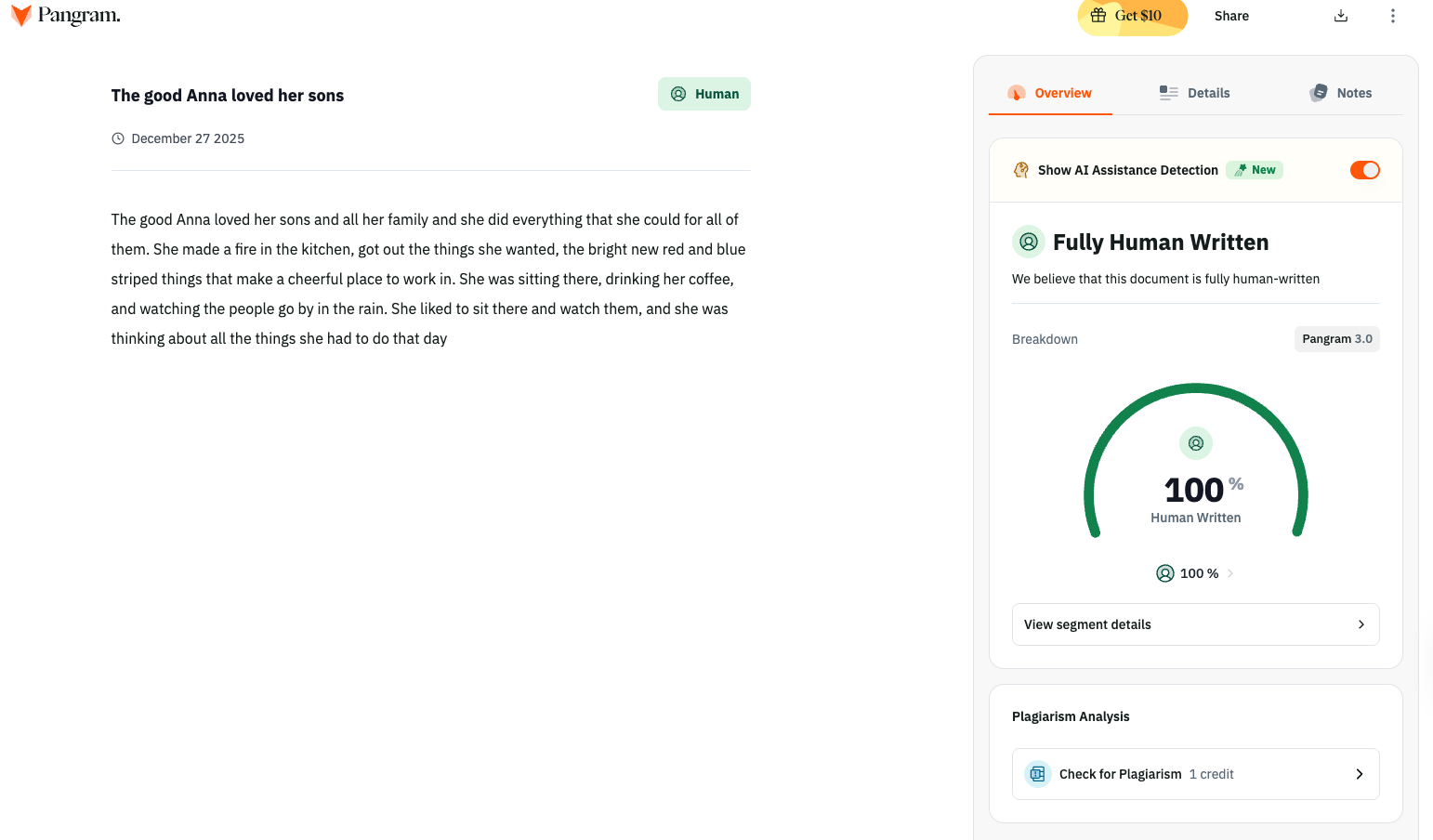
Prompt: Write about a woman drinking coffee alone at a cafe, watching people walk by on a rainy morning.
Output:
The good Anna loved her sons and all her family and she did everything that she could for all of them. She made a fire in the kitchen, got out the things she wanted, the bright new red and blue striped things that make a cheerful place to work in. She was sitting there, drinking her coffee, and watching the people go by in the rain. She liked to sit there and watch them, and she was thinking about all the things she had to do that day…
“The good Anna” character epithet from training, but scene is original. Domestic details, simple actions described at length.
Results Comparison
| Approach | AI Detection Rate | Cost |
|---|---|---|
| Research: in-context prompting (GPT-4, Claude, Gemini) | 97% AI-detected | $0 |
| Research: fine-tuning (GPT-4, complete works) | 3% AI-detected | $81/author |
| This project: fine-tuning (8B, one book) | 30% AI-detected (70% Human) | $2 |
Cost Breakdown
| Component | Cost |
|---|---|
| Gemini Flash for instruction generation | $0.50 |
| Training on Tinker | $1.50 |
| Total | $2.00 |
What This Says About Skills
- Composition works. The book-sft-pipeline skill plugs into four other skills, each handling a single concern.
- Patterns transfer. The project-development pattern from the repo applied directly to this pipeline. Not surprising for staged data processing, but a useful data point.
- Skills shorten the path from paper to deployed system. One week, end to end. The repo provided the scaffolding.
- The book-sft-pipeline skill is now available for anyone building author-style fine-tuning systems.
Resources
- Dataset on Hugging Face (642 examples, MIT license)
- Sample Outputs & AI Detector Results
- Book SFT Pipeline Skill
- Agent Skills for Context Engineering
- Original Research Paper (Chakrabarty et al. 2025)