Memory Routing Model
ActiveFine-tuned an 8B Llama model on memory routing for marketing conversations using prompt distillation and reinforcement learning on Tinker.
Training an 8B Memory Routing Model on Tinker
I have spent two years building marketing agent systems, context orchestration pipelines, and AI personas. I have written a lot of system prompts, built evaluation frameworks, and shipped production agents. I had not trained a model.
This project closes that gap. Using Claude Opus 4.5 in Cursor and Tinker (by Thinking Machines) as the training platform, I fine-tuned an 8B Llama on a narrow classification task: memory routing for marketing conversations. On a 50-scenario benchmark the fine-tuned 8B model scores higher than the 104B teacher used to generate its training data. Below is the full pipeline, what broke, and what I would do differently.
The motivating problem: when an agent embodies an expert marketing strategist, one of the core decisions is memory routing — what from a conversation deserves long-term storage, and at what scope.
User: “Our brand voice is professional but approachable. Think Harvard Business Review meets Slack.”
This is
company.brand_core- store it forever. It defines how every piece of content should sound.
User: “Can you check if the Q3 deck is ready?”
This is
none- transactional, no long-term value.
User: “I prefer bullet points over paragraphs. Get to the point quickly.”
This is
user.communication_style- personal preference that should persist across sessions.
But what about:
User: “Our philosophy is ‘measure twice, cut once’. We’d rather delay a launch than ship something half-baked.”
Is this
company.strategic_signatures(a decision framework) orcompany.brand_core(a value statement)? Both are valid. The model needs to understand the distinction.
I had 13 categories across company and user scopes, plus none for irrelevant content. Multi-label is allowed. Persistence horizons range from 2 weeks to 1+ years. This is a challenging classification problem.
I could call an LLM for every routing decision. But:
- Latency: Memory routing happens on every conversation turn. 200ms+ API calls add up.
- Cost: At scale, per-token pricing for classification is wasteful.
- Control: I wanted deterministic behavior. General-purpose models are too variable.
- Privacy: Some client data can’t leave the infrastructure.
The solution: train a small, specialized model that runs fast and cheap while matching or exceeding large model quality.
The Approach: Prompt Distillation with Tinker
Prompt distillation uses a large model to generate training data, then trains a smaller model to replicate (and ideally exceed) that behavior.
- Data Generation: Cohere Command-R-Plus (104B) generates 2,001 labelled marketing conversations (nothing particular with this model, I just had credits with Cohere and needed a model without rate limit issues.)
- SFT (Supervised Fine-Tuning): Train Llama-3.1-8B with LoRA to match the teacher’s outputs
- RL (Reinforcement Learning): Optimize for exact category matching with a custom reward function
- Evaluation: Benchmark against the teacher on held-out scenarios
I got access to Tinker and used it as the training platform because:
- Async API design: Overlap forward/backward passes with optimizer steps
- Built-in loss functions:
cross_entropyfor SFT,importance_samplingfor RL - LoRA support: Rank 32 adapters, no full fine-tuning required
- Checkpoint management: Save and resume training seamlessly
- Excellent documentation: Every API explained with examples and edge cases
The documentation was genuinely very easy to understand.
Phase 1: Synthetic Data Generation
The First Attempt (And Why It Failed)
My initial prompt to Cohere was too generic:
Generate a marketing conversation that demonstrates [category].
Include realistic details.The result: 1,000 conversations about sustainable fashion brands and eco-friendly packaging. The model latched onto “marketing” and generated variations of the same scenario.
The Fix: Structured Diversity
I built a generation pipeline with explicit diversity controls:
INDUSTRIES = ["fintech", "healthcare", "SaaS", "e-commerce", "agency",
"CPG", "media", "education", "legal", "manufacturing"]
USER_ROLES = ["CMO", "VP Growth", "Brand Manager", "Performance Marketer",
"Content Lead", "Demand Gen", "Product Marketing"]
TURN_COUNTS = [3, 4, 5, 6, 7, 8] # Conversation length variationEach generation randomly samples from these pools. The prompt explicitly instructs:
Create a realistic marketing conversation between a {role} at a {industry}
company and their AI assistant. The conversation should be {turns} turns long.
CRITICAL: This is a MID-CONVERSATION excerpt. No greetings, no "Hi, how can
I help you today?" Start in the middle of a substantive discussion.The “mid-conversation” constraint was crucial. Early data was polluted with greeting patterns that added no signal.
Balancing Category Distribution
My first dataset was severely imbalanced:
| Category | Percentage |
|---|---|
| user.strategic_approach | 34.5% |
| company.brand_core | 18.2% |
| company.tools_config | 0.5% |
| none | 3.1% |
The model learned to predict user.strategic_approach for everything.
I regenerated with explicit category targets:
CATEGORY_TARGETS = {
"company.brand_core": 77,
"company.strategic_signatures": 77,
"company.tools_config": 77, # Previously under-represented
"none": 154, # 2x weight for negative examples
# ... etc
}The none category needed extra weight. Models hate saying “nothing here” - they want to find patterns. Robust negative training requires more examples.
Temperature and Diversity
Even with structured prompts, outputs were too similar. The fix:
temperature=0.95 # High creativityPlus removing prescriptive examples from prompts. Instead of:
Example: "Our brand is built on transparency and trust..."I used:
The conversation MUST strongly exemplify {category}.
Definition: {category_definition}
Invent SPECIFIC and UNIQUE details relevant to a {industry} company.Let the model be creative within constraints.
Phase 2: Supervised Fine-Tuning with Tinker
The Training Loop
Tinker’s async API lets you overlap computation:
for step in range(num_steps):
# Submit forward-backward pass
fwd_bwd_future = await training_client.forward_backward_async(
batch_data,
loss_fn="cross_entropy",
)
# Submit optimizer step (can overlap)
optim_future = await training_client.optim_step_async(adam_params)
# Wait for both
fwd_bwd_result = await fwd_bwd_future.result_async()
optim_result = await optim_future.result_async()This matters for throughput. You’re not waiting for one operation to complete before starting the next.
Hyperparameters
Tinker provides get_lr() which returns the LoRA-optimized learning rate for your model:
from tinker_cookbook.hyperparam_utils import get_lr
learning_rate = get_lr("meta-llama/Llama-3.1-8B") # Returns ~2.86e-4No manual tuning. The docs explain the scaling: LoRA adapters need higher LRs than full fine-tuning because you’re updating fewer parameters.
Key settings:
- LoRA rank: 32 (Tinker default for classification)
- Batch size: 128
- Steps: 100 (with early stopping)
- Optimizer: Adam (β1=0.9, β2=0.95, ε=1e-8)
The save_state vs save_weights_for_sampler Bug
This cost me hours. Tinker has two checkpoint methods:
save_weights_for_sampler(): Saves weights for inference onlysave_state(): Saves full training state (weights + optimizer + step count)
I used save_weights_for_sampler() for my SFT checkpoint. When I started RL, the training client couldn’t load optimizer state. RL started from scratch, ignoring all SFT progress.
The fix:
# For SFT final checkpoint that RL will continue from:
sft_checkpoint = training_client.save_state(name="sft_final")
# For intermediate checkpoints you'll only use for inference:
sampling_checkpoint = training_client.save_weights_for_sampler(name="sft_step_50")The docs explain this, but I skimmed too fast. Claude caught it when debugging why RL showed 0% accuracy for 5 iterations.
SFT Results
Loss dropped from 5.47 to 0.26 (95% reduction) over 100 steps:
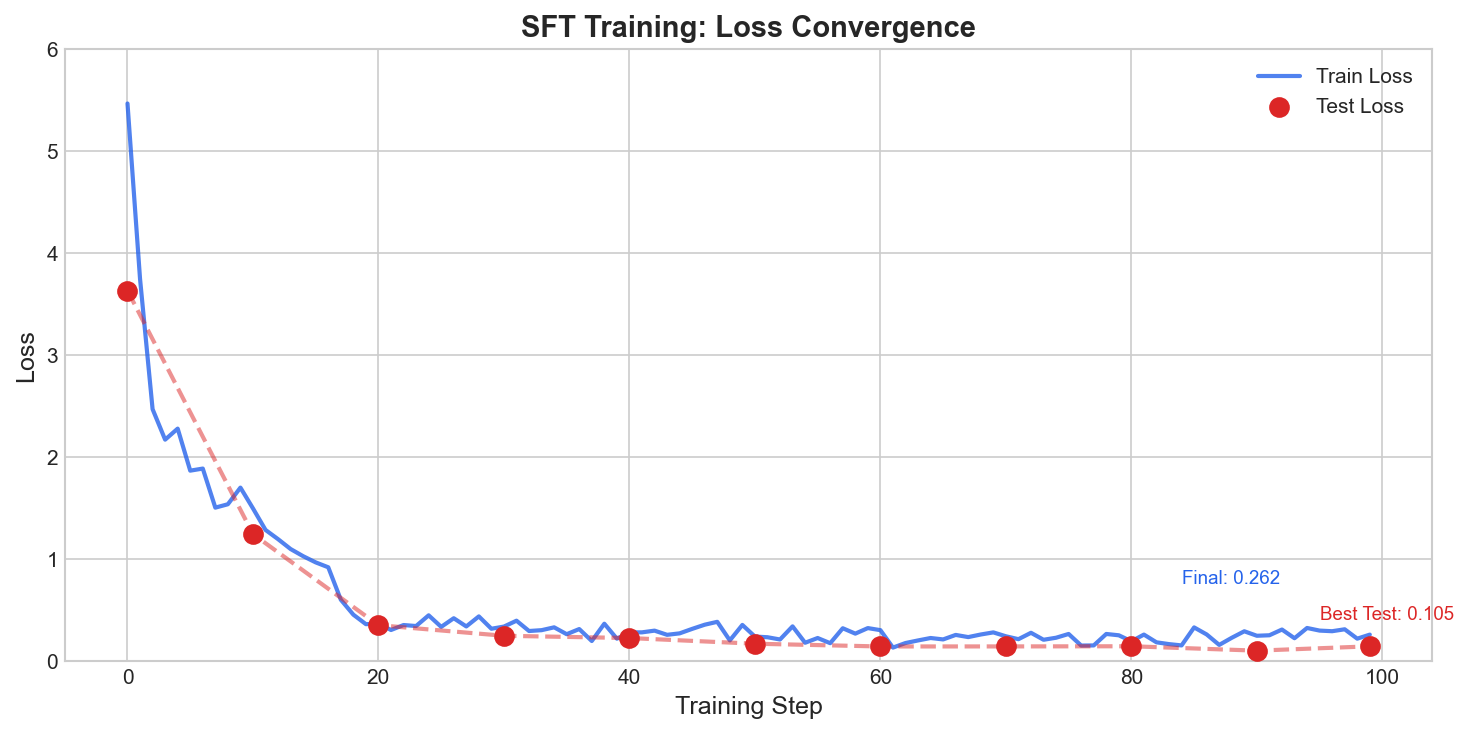
The model learned the task quickly. By step 20, test loss was already at 0.35. The remaining steps refined edge cases.
Phase 3: Reinforcement Learning
SFT gets you 80% of the way. The model outputs plausible categories. But it doesn’t optimize for exact matching - it optimizes for token-level cross-entropy.
RL fixes this by directly rewarding correct classification.
The Reward Function
R_total = 0.6 * R_F1 + 0.2 * R_temp + 0.1 * R_parity + 0.1 * R_eff| Component | Weight | Description |
|---|---|---|
| R_F1 | 60% | F1 score vs gold labels |
| R_temp | 20% | Persistence horizon alignment (long/medium/short) |
| R_parity | 10% | Company/user scope correctness |
| R_eff | 10% | Storage efficiency (≤3 categories preferred) |
The weights encode our priorities: get the categories right (F1), but also respect temporal semantics and avoid over-storing.
Importance Sampling
Tinker uses importance sampling for policy gradient:
fwd_bwd_future = await training_client.forward_backward_async(
train_data,
loss_fn="importance_sampling"
)This requires careful construction of the training data. Each datum needs:
input_tokens: The prompttarget_tokens: The model’s generated responselogprobs: Log probabilities of each target tokenadvantages: Reward signal (centered within groups)
The lengths must match exactly. I hit this error repeatedly:
tinker.BadRequestError: input sequence, target_tokens, logprobs, and
advantages at index 0 must have the same lengthThe fix was ensuring tokenization consistency between sampling and training.
KL Divergence Monitoring
Tinker’s RL hyperparameters docs emphasize KL monitoring for training stability:
# Two KL estimators per Tinker RL docs
kl_v1 = (old_logprobs - new_logprobs).mean() # Can be negative
kl_v2 = (torch.exp(old_logprobs - new_logprobs) - 1 - (old_logprobs - new_logprobs)).mean() # Always non-negative- Target: KL < 0.005
- Warning: KL 0.005-0.01
- Critical: KL > 0.01
My first RL runs had KL around -0.01 (negative). This is mathematically impossible for true KL divergence. The bug: I was computing new - old instead of old - new.
Advantage Computation
Rewards must be centered within groups for stable gradients:
# Wrong: use raw rewards
advantages = rewards
# Right: center within each group
group_mean = rewards.mean()
advantages = rewards - group_meanWithout centering, the model receives inconsistent gradient signals. Tinker’s docs explain this in the RL hyperparameters section.
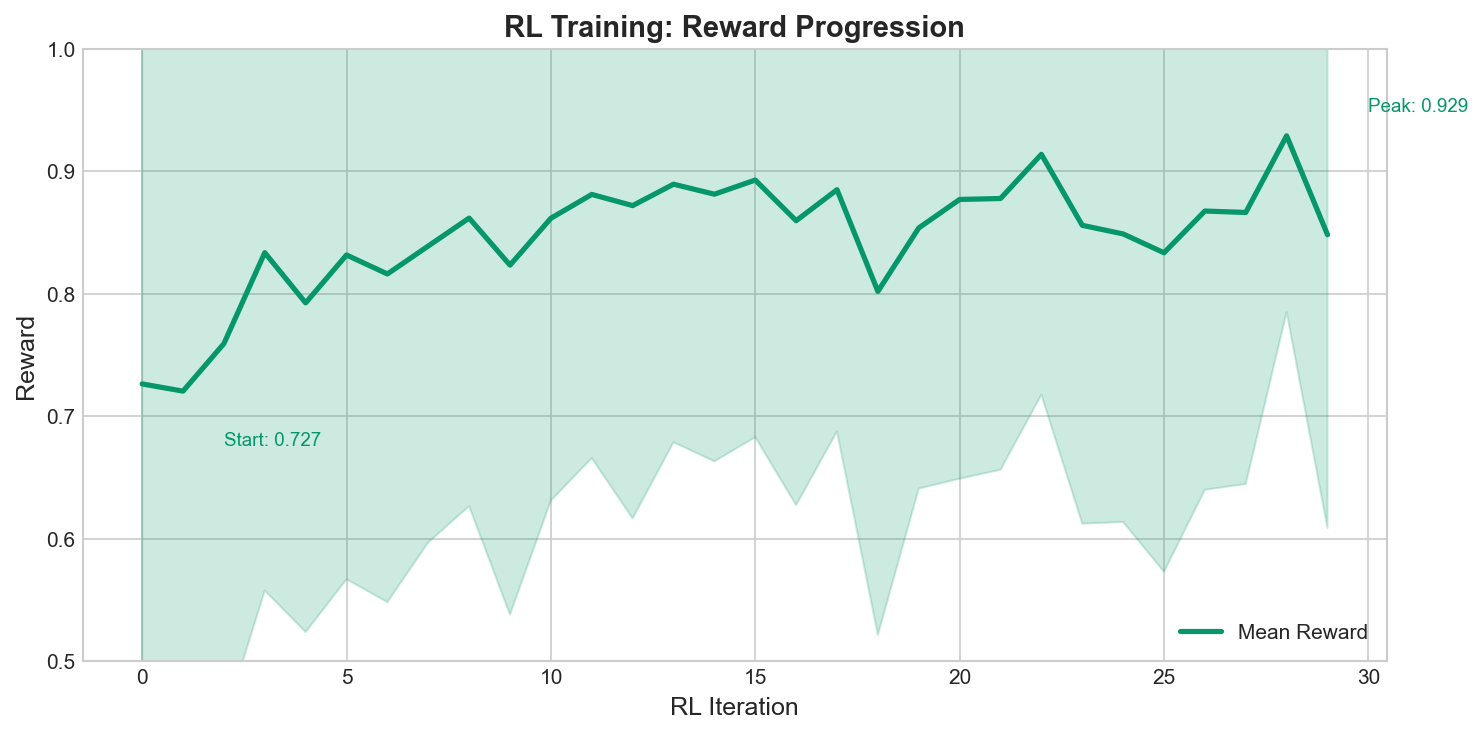
RL Results
30 iterations improved mean reward from 0.73 to 0.93:
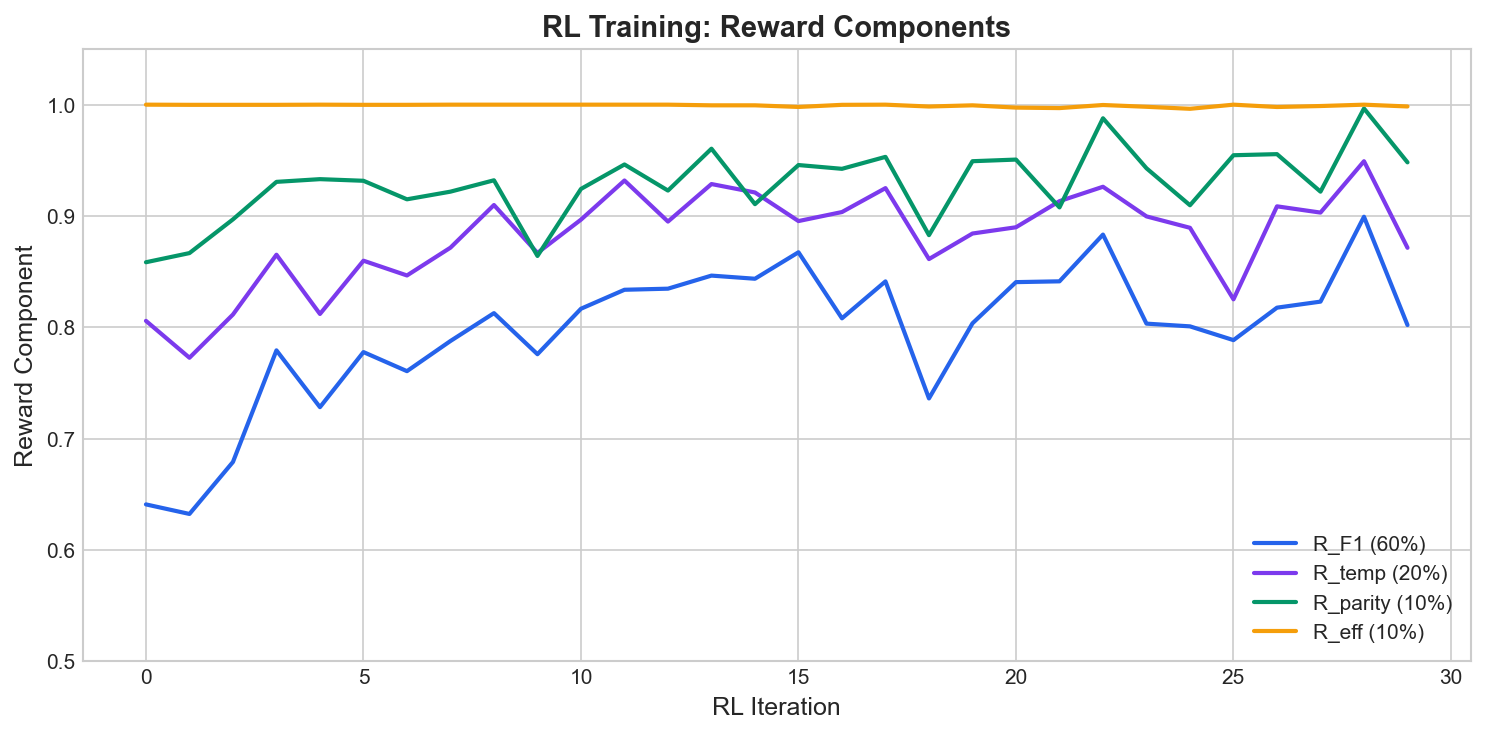
The reward components tell the story:
| Component | Start | End |
|---|---|---|
| R_F1 | 0.64 | 0.90 |
| R_temp | 0.81 | 0.95 |
| R_parity | 0.86 | 1.00 |
| R_eff | 1.00 | 1.00 |
F1 improved most (+40%). The model learned to get exact category matches, not just plausible outputs.
Evaluation: Student vs Teacher
I created a 50-scenario benchmark with challenging marketing cases across 7 domains:
| Domain | Scenarios |
|---|---|
| Brand & Positioning | 8 |
| Strategic Decisions | 8 |
| Performance & Metrics | 8 |
| Tools & Integrations | 6 |
| User Preferences | 10 |
| Business Priorities | 6 |
| Knowledge Artifacts | 4 |
Each scenario has difficulty ratings (easy/medium/hard) and expected categories.
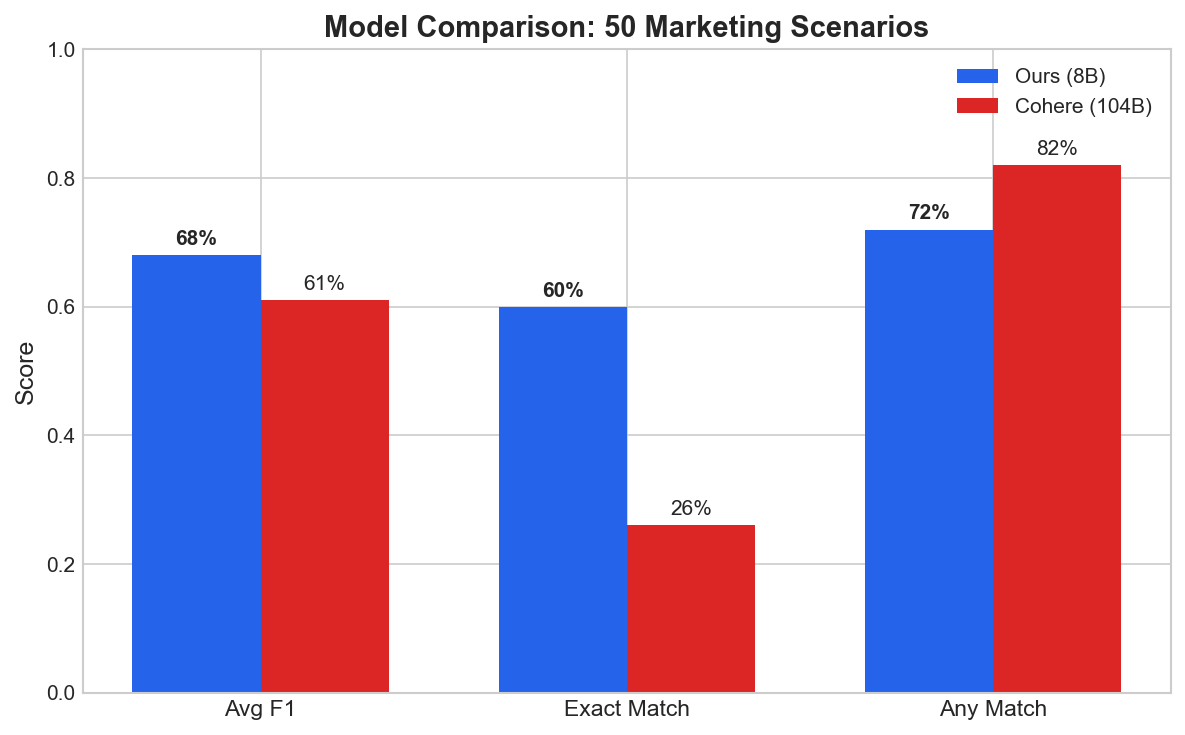
Results
| Model | Size | Avg F1 | Exact Match |
|---|---|---|---|
| Llama-8B + LoRA (this work) | 8B | 0.68 | 60% |
| Cohere Command-R-Plus | 104B | 0.61 | 26% |
The 8B model scores 11% higher on F1 and 2.3x on exact match. Important caveat: see the difficulty breakdown below — most of the lift comes from easy and medium cases, and the 104B teacher still wins on hard multi-label scenarios.
Performance by Difficulty
| Difficulty | Our Model | Cohere | Delta |
|---|---|---|---|
| Easy | 0.86 | 0.48 | +79% |
| Medium | 0.65 | 0.64 | +2% |
| Hard | 0.50 | 0.72 | -31% |
The 8B model wins on easy cases and matches on medium. The 104B teacher still wins on hard multi-label scenarios where three or more categories apply. The aggregate lift is real, but the comparison favors the student because most benchmark cases are not hard.
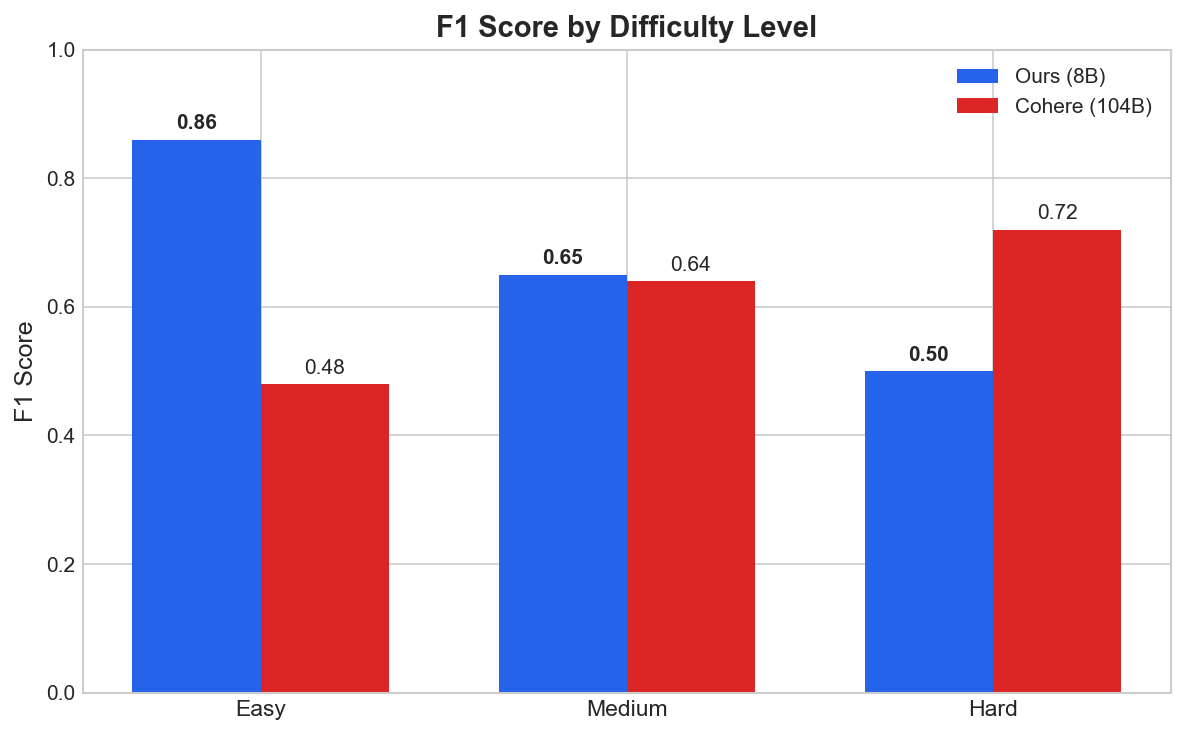
Why does the student outperform on aggregate?
Three reasons:
-
Specialization. The 8B model does one thing. The teacher is a general-purpose 104B model optimized for many tasks.
-
RL objective. Cross-entropy (SFT) rewards plausible outputs. The reward function used here explicitly rewards exact category matching, which the teacher was never optimized for.
-
Clean data. Synthetic labels have no annotator disagreement, so the model learns one consistent decision boundary instead of the average of conflicting human labels.
This is the well-known specialization vs. generalization trade-off; the result is not unique to this task, and it does not transfer to harder distributions.
Working with Claude
I had not used PyTorch for training, written a reward function, or debugged gradient issues before this. What I had was a year of building AI systems: enough to decompose problems, iterate on failures, and read documentation carefully. Claude filled the implementation gap.
Three things made this productive:
1. Framing prompts as architectural questions, not codegen requests
Instead of “write me an RL training loop,” prompts like:
“What would you check first when RL shows 0% accuracy for 5 iterations? Challenge my assumptions about checkpoint state.”
surfaced the save_state vs save_weights_for_sampler bug by reasoning about what state RL needs to resume training.
2. Reading docs in the loop
Tinker’s documentation is dense but good. Paste a section, describe the bug, and Claude could connect them:
- When async operations can overlap vs must be sequential
- Why LoRA needs different learning rates
- How importance sampling differs from vanilla policy gradient
- What KL divergence thresholds indicate training instability
3. Iteration count
Roughly 50 iterations end to end:
- Synthetic data too homogeneous → fix prompt diversity.
- Category distribution imbalanced → fix generation targets.
- KL divergence negative → fix computation order.
- Advantages not centered → fix group normalization.
- RL started from scratch → fix checkpoint method.
Each cycle: run, observe, diagnose, fix.
Lessons Learned
On Prompt Distillation
-
A specialized small model can outperform a generalist teacher on a narrow distribution. This is well-known and tells you nothing about general capability.
-
Data quality matters more than quantity. The first 1,000 examples were too similar. The second 1,000, with higher temperature and diverse prompts, helped more than doubling the dataset would have.
-
Negative examples are important. Models bias toward finding patterns. The
nonecategory needed roughly 2x the examples to learn robust rejection. -
RL is powerful but finicky. SFT gets you most of the way. RL handles the last bit but adds more failure modes: reward hacking, KL explosion, gradient instability.
On Tinker
- The documentation is dense but accurate, with examples and edge cases for most APIs.
- The async API improves throughput by letting forward/backward overlap with optimizer steps.
- Checkpoint semantics matter: know the difference between
save_state()andsave_weights_for_sampler(). - Monitor KL divergence. If it exceeds 0.01, something is wrong upstream.
On AI-Assisted Development
- Treat the assistant as a reviewer first, code generator second. Ask it to challenge assumptions and identify failure modes.
- Iterate fast. Most experiments fail; learning velocity matters more than first-attempt success.
- Give it the full stack trace, not just the final line.
- Log metrics every step. If something goes wrong, you need to trace exactly where.
What’s Next
The model is open-source:
- HuggingFace: MuratcanKoylan/Marketing-Memory-Routing-8B
- GitHub: muratcankoylan/memory-routing-agent
Roadmap:
- Train on larger dataset (10k+ examples)
- Test different base models (Qwen, Mistral)
- Add per-category evaluation metrics
- Deploy to production
Final Thoughts
The gap between using AI and training AI is narrowing. With Tinker, an assistant like Claude, and the willingness to iterate through failures, training a specialized model is now accessible to engineers who are not ML researchers.
This model is narrow. It still loses to the teacher on hard multi-label cases. It is 13x smaller and good enough for the routing task it was built for. If you are thinking about training your first model: pick a narrow problem, generate some data, train something, see what breaks, and iterate.
Thanks to Thinking Machines for Tinker. Thanks to Cohere for the teacher model, Meta for Llama, and Anthropic for Claude.
Links:
Gallery